
ML Day 1 — Introduction to ML!!!
- SD Prasad
- Nov 12, 2020
- 10 min read

This just in… One more person in the world wanting to learn Machine Learning. 😉 (Free Resources here !!)
Motivation :- I have always wanted to make a Unique project that I can proudly say was made by me. I found the voice tech domain that looked promising and very interesting to me. One can’t make apps from the scratch using the limited knowledge that one has and hence ML.
The best way to learn something is by teaching it so I’ll share everyday what I ‘ve learnt and hope that makes things etched on my brain longer and hope it helps you in someway as well.
Planning: —
A big shoutout to Love Babbar’s Youtube video (I know the name’s a bit weird but what can you do) for making all the resources clear and the Roadmap more understandable. Based on this video it should take me around 6–9 months to properly understand and apply ML apps from
Creation →Production →Public. I hope it takes lesser time.
Another video that I really liked was Daniel Bourke’s Roadmap Video.

COURTSEY— Daniel Bourke (For Full Road Map)
Resources : —
Books:-
1. Hands on Machine Learning with Scikit-Learn, Keras and Tensorflow (2nd Edition) 2. Mathematics for Machine Learning
You don’t necessarily need to know the under the hood mathematics behind each algorithm until you do, so I thought why skip it. Also, I don’t promote this but these resources are available for free in Z-Library.
Websites (Basics):-
Websites (Advanced):-
1. Deep Learning.ai by Andrew Ng 2. Fast.ai ( Part 1 and Part 2) 3. CS50 Into to AI in Python by Harvard
Testing the Skills into Action:-
1. Kaggle 2. Workera.ai

PROGRESS
So what did I actually learn on my Day 1.
1. Why ML?
•Problems for which existing solutions require a lot of hand-tuning or long lists of rules: one Machine Learning algorithm can often simplify code and perform better.
• Complex problems for which there is no good solution at all using a traditional approach: the best Machine Learning techniques can find a solution.
• Fluctuating environments: a Machine Learning system can adapt to new data.
• Getting insights about complex problems and large amounts of data.


2. Types of ML Systems ?
There are different types of ML systems
One that can either learn on its own or need Human Intervention, i.e. Supervised or Unsupervised ML.
Whether or not they can learn incrementally on the fly ( Online v/s Batch)
Do they work by comparing new data points to known ones or instead detect patters in the training data and build predictive models.
2 a. Supervised/Unsupervised Learning
In Supervised Learning, the training data you feed to the algorithm includes the desired solutions, called labels.

A typical supervised learning task is classification. The spam filter is a good example of this: it is trained with many example emails along with their class (spam or ham), and it must learn how to classify new emails. Another typical task is to predict a target numeric value, such as the price of a car, given a set of features (mileage, age, brand, etc.) called predictors. This sort of task is called regression. To train the system, you need to give it many examples of cars, including both their predictors and their labels.
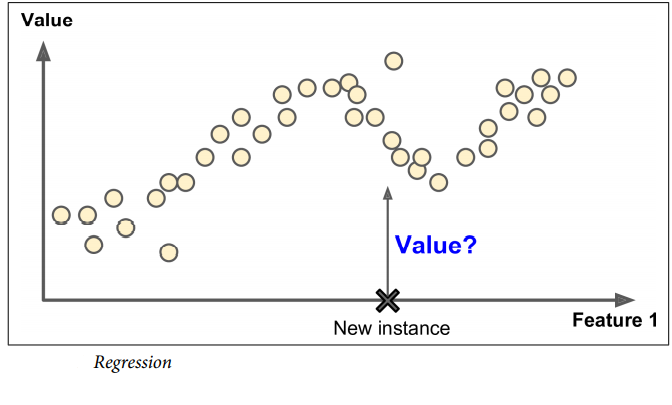
Note that some regression algorithms can be used for classification as well, and vice versa. For example, Logistic Regression is commonly used for classification, as it can output a value that corresponds to the probability of belonging to a given class (e.g., 20% chance of being spam).
Here are some of the most important supervised learning algorithms:
k-Nearest Neighbors
Linear Regression
Logistic Regression
Support Vector Machines (SVMs)
Decision Trees and Random Forests
Neural networks
In unsupervised learning, as you might guess, the training data is unlabeled. The system tries to learn without a teacher.
Here are some of the most important unsupervised learning algorithms
Clustering : —
For example, say you have a lot of data about your blog’s visitors. You may want to run a clustering algorithm to try to detect groups of similar visitors . At no point do you tell the algorithm which group a visitor belongs to: it finds those connections without your help. For example, it might notice that 40% of your visitors are males who love comic books and generally read your blog in the evening, while 20% are young sci-fi lovers who visit during the weekends, and so on. If you use a hierarchical clustering algorithm, it may also subdivide each group into smaller groups. This may help you target your posts for each group.

K-Means
DBSCAN
Hierarchical Cluster Analysis (HCA)
Anomaly detection and novelty detection :—
Yet another important unsupervised task is anomaly detection — for example, detecting unusual credit card transactions to prevent fraud, catching manufacturing defects, or automatically removing outliers from a dataset before feeding it to another learning algorithm. The system is shown mostly normal instances during training, so it learns to recognize them and when it sees a new instance it can tell whether it looks like a normal one or whether it is likely an anomaly (see Figure 1–10). A very similar task is novelty detection: the difference is that novelty detection algorithms expect to see only normal data during training, while anomaly detection algorithms are usually more tolerant, they can often perform well even with a small percentage of outliers in the training set.

One-class SVM
Isolation Forest
Visualization and dimensionality reduction :—
Visualization algorithms are also good examples of unsupervised learning algorithms: you feed them a lot of complex and unlabeled data, and they output a 2D or 3D representation of your data that can easily be plotted. These algorithms try to preserve as much structure as they can (e.g., trying to keep separate clusters in the input space from overlapping in the visualization), so you can understand how the data is organized and perhaps identify unsuspected patterns.

Principal Component Analysis (PCA)
Kernel PCA
Locally-Linear Embedding (LLE)
t-distributed Stochastic Neighbor Embedding (t-SNE)
Association rule learning :—
Finally, another common unsupervised task is association rule learning, in which the goal is to dig into large amounts of data and discover interesting relations between attributes. For example, suppose you own a supermarket. Running an association rule on your sales logs may reveal that people who purchase barbecue sauce and potato chips also tend to buy steak. Thus, you may want to place these items close to each other.
Apriori
Eclat
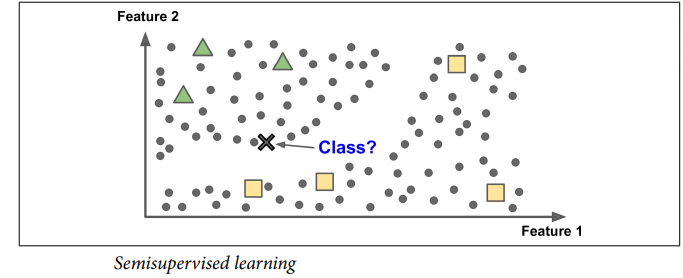
Semi supervised learning, some algorithms can deal with partially labeled training data, usually a lot of unlabeled data and a little bit of labeled data. Most semi supervised learning algorithms are combinations of unsupervised and supervised algorithms.
Some photo-hosting services, such as Google Photos, are good examples of this. Once you upload all your family photos to the service, it automatically recognizes that the same person A shows up in photos 1, 5, and 11, while another person B shows up in photos 2, 5, and 7. This is the unsupervised part of the algorithm (clustering). Now all the system needs is for you to tell it who these people are. Just one label per person, and it is able to name everyone in every photo, which is useful for searching photos.
Reinforcement Learning is a very different beast. The learning system, called an agent in this context, can observe the environment, select and perform actions, and get rewards in return (or penalties in the form of negative rewards). It must then learn by itself what is the best strategy, called a policy, to get the most reward over time. A policy defines what action the agent should choose when it is in a given situation.

For example, many robots implement Reinforcement Learning algorithms to learn how to walk. DeepMind’s AlphaGo program is also a good example of Reinforcement Learning: it made the headlines in May 2017 when it beat the world champion Ke Jie at the game of Go. It learned its winning policy by analyzing millions of games, and then playing many games against itself. Note that learning was turned off during the games against the champion; AlphaGo was just applying the policy it had learned.
2b. Batch and Online Learning
Can the ML systems learn incrementally from a stream of incoming data? Oh yes we can!!!😉
Batch learning
In batch learning, the system is incapable of learning incrementally: it must be trained using all the available data.
Takes a lot of time and computing resources, so done offline.
Trained →Launched in Production → Runs w/o Learning, applies what it has learned.
Finally, if your system needs to be able to learn autonomously and it has limited resources (e.g., a smartphone application or a rover on Mars), then carrying around large amounts of training data and taking up a lot of resources to train for hours every day is a showstopper. Fortunately, a better option in all these cases is to use algorithms that are capable of learning incrementally.
Online learning
In online learning, you train the system incrementally by feeding it data instances sequentially, either individually or by small groups called mini-batches. Each learning step is fast and cheap, so the system can learn about new data on the fly, as it arrives.
Online learning is great for systems that receive data as a continuous flow (e.g., stock prices) and need to adapt to change rapidly or autonomously. It is also a good option if you have limited computing resources: once an online learning system has learned about new data instances, it does not need them anymore, so you can discard them (unless you want to be able to roll back to a previous state and “replay” the data). This can save a huge amount of space.

Online learning algorithms can also be used to train systems on huge datasets that cannot fit in one machine’s main memory (this is called out-of-core learning). The algorithm loads part of the data, runs a training step on that data, and repeats the process until it has run on all of the data.

2c Instance-Based Versus Model-Based Learning

Instance-based learning, This is called instance-based learning: the system learns the examples by heart, then generalizes to new cases by comparing them to the learned examples (or a subset of them), using a similarity measure.

Model-based learning, another way to generalize from a set of examples is to build a model of these examples, then use that model to make predictions. This is called model-based learning
3. Main Challenges of Machine Learning
In short, since your main task is to select a learning algorithm and train it on some data, the two things that can go wrong are “bad algorithm” and “bad data.”

Bad Data:-
Insufficient Quantity of Training Data
Non-Representative Training Data In order to generalize well, it is crucial that your training data be representative of the new cases you want to generalize to. This is true whether you use instance-based learning or model-based learning.
Poor-Quality Data
Irrelevant Features
Bad Algorithms :-
Overfitting the Training Data
Underfitting the Training Data
4. Testing and Validating
The only way to know how well a model will generalize to new cases is to actually try it out on new cases. One way to do that is to put your model in production and monitor how well it performs. This works well, but if your model is horribly bad, your users will complain — not the best idea.
A better option is to split your data into two sets: the training set and the test set. As these names imply, you train your model using the training set, and you test it using the test set. The error rate on new cases is called the generalization error (or out of sample error), and by evaluating your model on the test set, you get an estimate of this error. This value tells you how well your model will perform on instances it has never seen before.
If the training error is low (i.e., your model makes few mistakes on the training set) but the generalization error is high, it means that your model is overfitting the training data.
5. Hyperparameter Tuning and Model Selection
So evaluating a model is simple enough: just use a test set. Now suppose you are hesitating between two models (say a linear model and a polynomial model): how can you decide? One option is to train both and compare how well they generalize using the test set.
Now suppose that the linear model generalizes better, but you want to apply some regularization to avoid overfitting. The question is: how do you choose the value of the regularization hyperparameter? One option is to train 100 different models using 100 different values for this hyperparameter. Suppose you find the best hyperparameter value that produces a model with the lowest generalization error, say just 5% error So you launch this model into production, but unfortunately it does not perform as well as expected and produces 15% errors. What just happened? The problem is that you measured the generalization error multiple times on the test set, and you adapted the model and hyperparameters to produce the best model for that particular set. This means that the model is unlikely to perform as well on new data.
Acommon solution to this problem is called holdout validation: you simply hold out part of the training set to evaluate several candidate models and select the best one. The new heldout set is called the validation set. The new heldout set is called the validation set (or sometimes the development set, or dev set). More specifically, you train multiple models with various hyperparameters on the reduced training set (i.e., the full training set minus the validation set), and you select the model that performs best on the validation set. After this holdout validation process, you train the best model on the full training set (including the validation set), and this gives you the final model. Lastly, you evaluate this final model on the test set to get an estimate of the generalization error.
6. WELL TO SUMMARIZE…
By now you already know a lot about Machine Learning. However, we went through so many concepts that you may be feeling a little lost, so let’s step back and look at the big picture:
Machine Learning is about making machines get better at some task by learning from data, instead of having to explicitly code rules.
There are many different types of ML systems: supervised or not, batch or online, instance-based or model-based, and so on.
In a ML project you gather data in a training set, and you feed the training set to a learning algorithm. If the algorithm is model-based it tunes some parameters to fit the model to the training set (i.e., to make good predictions on the training set itself), and then hopefully it will be able to make good predictions on new cases as well. If the algorithm is instance-based, it just learns the examples by heart and generalizes to new instances by comparing them to the learned instances using a similarity measure.
The system will not perform well if your training set is too small, or if the data is not representative, noisy, or polluted with irrelevant features (garbage in, garbage out). Lastly, your model needs to be neither too simple (in which case it will underfit) nor too complex (in which case it will overfit).
Stay tuned for more updates and sharing my learning, a comment below or a clap will be really great !!✌
Comments